Product Info
Godel Base B‑1:
A 200M-Parameter Sparse Mixture-of-Experts Language Model
At Atom Technologies, we are rethinking how large language models can be scaled efficiently while remaining accessible and performant across diverse applications. Godel Base B‑1 represents the first milestone in this journey: a mid-sized, open-source model designed to balance parameter count, inference speed, and modular architecture.
Model Overview
Godel Base B‑1 is a 200 million parameter transformer language model that integrates a Mixture-of-Experts (MoE) routing layer to deliver greater capacity without linear growth in compute requirements.
This architecture is built from the ground up for:
Efficient inference under constrained hardware budgets
Modular scaling by adding additional experts
Compatibility with modern tokenizers (like our T‑1) and training pipelines
Architecture Details
Godel Base B‑1 combines:
Dense transformer backbone
A standard transformer encoder-decoder stack responsible for contextual representation learning.Sparse MoE layers
Selectively activated experts controlled by a gating network, allowing the model to dynamically specialize without incurring the full cost of dense layers.
Core Components
1. Embedding Layer
Vocabulary Size: 6,000 (T‑1 tokenizer)
Embedding Dimension: 512
2. Transformer Blocks
24 transformer layers
Multi-head self-attention (8 attention heads per layer)
Pre-layer normalization
Feed-forward hidden dimension: 2048
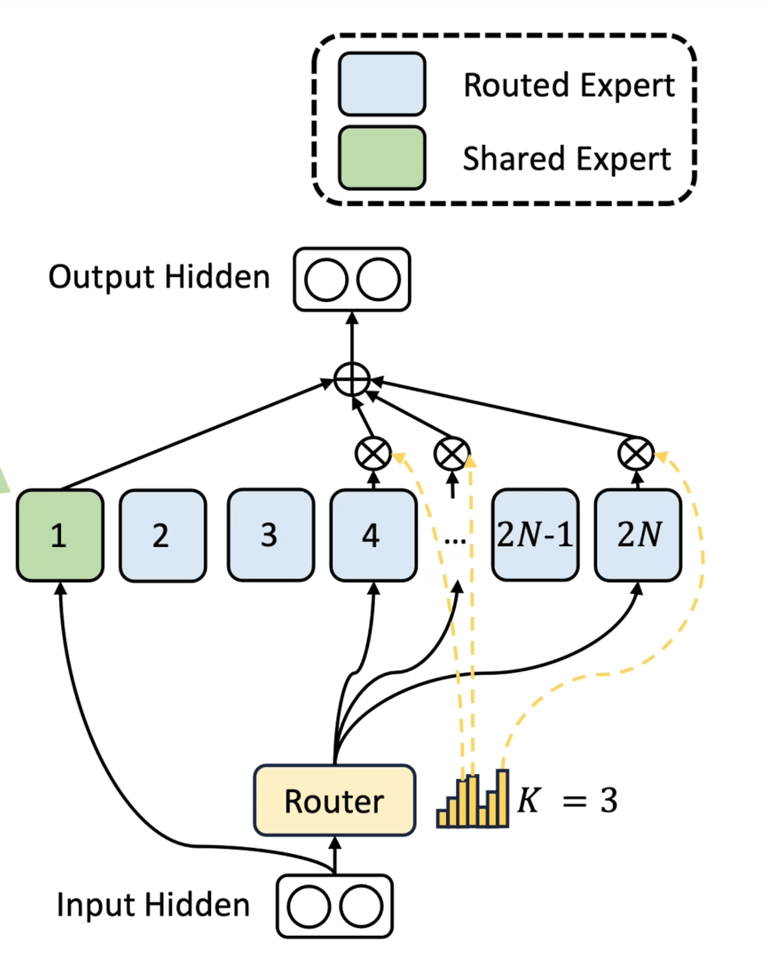
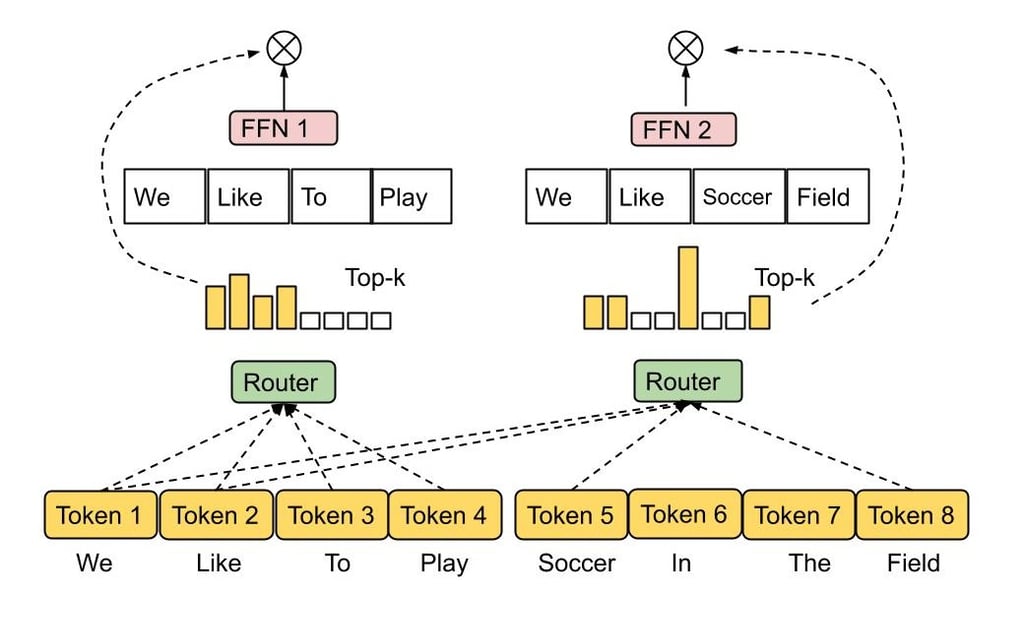
3. MoE Layer
16 experts in total
Sparse routing: Top-2 expert selection per token
Each expert: independent feed-forward network
Gating network: softmax gating probabilities to control expert activation
4. Output Projection
Linear projection to vocabulary logits
Softmax for final token probabilities
Mixture-of-Experts Design
Godel Base B‑1’s MoE implementation is inspired by approaches proven in research (Switch Transformer, DeepSeek-V3):
Sparse Activation: Only 2 out of 16 experts are active for each input token.
Load Balancing Loss: Auxiliary loss term encourages uniform utilization of experts.
Capacity Factor: Adjustable hyperparameter controlling expert selection granularity.
This enables a model with an effective capacity far larger than a dense 200M-parameter transformer, while maintaining efficient memory and compute usage.
Training Objectives
The model is pretrained on large-scale English and domain-specific corpora using:
Masked Language Modeling
Next Token Prediction
Auxiliary MoE load balancing regularization
Optimization uses AdamW with a cosine learning rate schedule and mixed-precision training for speed and stability.
Performance Goals
Godel Base B‑1 is designed to deliver:
Competitive perplexity relative to larger dense models
Faster inference due to sparse expert activation
Robust handling of domain-specific text without specialized fine-tuning
While smaller than flagship multi-billion parameter LLMs, B‑1 prioritizes deployability and adaptability.
Open-Source Roadmap
Godel Base B‑1 will be fully open-sourced, including:
Pretrained weights
Model architecture definitions (PyTorch)
Tokenizer artifacts
Training recipes and hyperparameters
Our goal is to make high-quality foundation models transparent, reproducible, and accessible to the broader ML community.
Use Cases
Potential applications include:
General-purpose text generation and summarization
Task-oriented dialog systems
Code completion and lightweight programming assistance
Research and experimentation with sparse expert models
Conclusion
Godel Base B‑1 is a new approach to scaling mid-sized language models: combining sparse Mixture-of-Experts with a streamlined transformer backbone and open-source philosophy. This architecture establishes a flexible foundation for future models and extensions, including larger parameter counts and more specialized expert modules.
Stay tuned for model releases, technical papers, and integration guides.